In diesem Posting will ich kurz erklären, wie ich beim Durchschauen der 260000 Bilder der ETH-Library vorgehe. Eine Viertel-Million Bilder ist eine enorme Menge. Je nach Dauer der Betrachtung und Anzahl der ausgewählten Bilder kommt man auf Wochen und Monate, die man da vor dem Bildschirm verbringt – nicht eingerechnet die Zeit, die man mit Warten verbringt, weil der Bild-Server oder das Internet oder der eigene Rechner einen immer wieder "hängen lassen ...".
Man muss sich überlegen: Wenn man sich je Bild eine Sekunde an Arbeit erspart, dann sind das 260000 / 86400 = 3 volle Tage, die man für andere Hobbies an Zeit gewinnt: Es zahlt sich also aus, den Bearbeitungsprozess möglichst zu optimieren, damit man wenigstens nur Zeit für das aufwendet, das sowieso gemacht werden muss: Bilder betrachten, entscheiden, Texte formulieren ...
Ohne eine Software geht es nicht; die soll aber so einfach wie möglich sein. Und ohne ein Eingehen auf alle Aspekte dieser Arbeit geht es auch nicht – man muss sich zumindest mit einigen praktischen
- psychologischen,
- ergonomischen und natürlich auch
- technischen
Daten 1
Die Webseite der ETH-Bibliothek bietet seit kurzem nicht mehr die Möglichkeit, dass man sich durch die Bilder "durchklickt". Das hat mich zuerst irritiert, im Nachhinein hat sich das aber als Segen erwiesen, weil ich mir eine kleine Software schreiben konnte, die vollkommen unabhängig von den Features auf der Webseite ist – alles, was ich brauche, sind Links zu all den Bildern. Dazu hat mir die ETH-Bibliothek auf Nachfrage dankenswerterweise fünf CSV-Dateien zur Verfügung gestellt, die durch Semikolon getrennt folgende Informationen enthalten:
- Den Bildcode, das ist eine eindeutige Identifikation des Bildes (in diesem Fall sind das Zeichenketten, die mit "SIK" beginnen);
- einige Felder, die den Inhalt mehr oder weniger gut beschreiben;
- zuletzt ein stabiler DOI-Link (ein normaler https-Link mit Domain doi.org) zum Öffnen einer Seite mit dem Bild und den Bildinformationen.
Nach Rückfrage bei der ETH-Bibliothek habe ich die Dateien (mit ASCII-Encoding und nach Bildcode sortiert) nun auch hier zum Download verlinkt, wenn jemand selbst an einer Weiterverarbeitung interessiert ist:
- SIK_01.sorted.csv (ca. 7 MB)
- SIK_02.sorted.csv (ca. 3 MB)
- SIK_03.sorted.csv (ca. 12 MB)
- SIK_04.sorted.csv (ca. 5 MB)
- SIK_05.sorted.csv (ca. 2 MB)
Software-Design
Meine Software muss ergonomisch bedienbar sein: Jede unnötige Bewegung kostet nur Zeit. Da zumindest ein Teil der Arbeit an der Tastatur erfolgen muss (Texterstellung, eventuell Suchen), sollten also auch alle anderen Aktionen über die Tastatur erfolgen; und dort, ohne dass Tasten nur zur Aktionsauswahl gedrückt werden müssen (Wechseln in ein Menü o.ä.). Die klassische Lösung für dieses Problem ist ein "Command-Line-Interface", also die Verwendung von Textbefehlen. Und weil ich den uralten AWK besser beherrsche als alle Shell-Sprachen der Welt, habe ich mich dafür entschieden, mein Toolchen damit zu schreiben. Gnu-AWK 4.1.3 gibt es als Windows-EXE, damit lege ich los.
Daten 2
Die Daten aus einer CSV-Datei (oder auch mehreren) lege ich drei "associative arrays" ab:
- id[i] enthält für i=1, 2, ... den Bildcode des i-ten Bildes.
- ln[i] enthält den DOI-Link des i-ten Bildes.
- tx[i] enthält alle die Felder dazwischen.
BEGIN {
FS = ";"
for (n = 1; getline < csvfile; n++) {
id[n] = $1
ln[n] = $NF
for (j = 2; j <= NF - 1; j++) tx[n] = tx[n] $j ";"
}
}
Programmaufbau
Alles weitere erfolgt durch Lesen des stdin: Dort gebe ich Befehle ein, die jeweils als regulärer Ausdruck erkannt werden. Nach jedem Befehl wird zumindest ein Prompt ausgegeben, bei vielen Befehlen aber natürlich ein Bild angezeigt. Der Aufbau des Gesamtprogramms sieht daher so aus;
/Befehlsmuster/ {
Befehl ausführen
prompt()
next
}
...
/Befehlsmuster/ {
Befehl ausführen
showAndPrompt(i)
next
}
...
prompt() und showAndPrompt()
Das Anzeigen eines Prompts ist ein einfaches printf eines (vorerst) Größer-Zeichens (im Gegensatz zu print wird dort am Ende kein Newline erzeugt, was ich mir hier wünsche):
function prompt(){Wie öffnet man ein Bild, wenn man den DOI-Link hat? Das geht einfach: Auf der Kommandozeile start microsoft-edge:DOI-Link eingeben (habe ich irgendwo bei Stackoverflow gefunden). showAndPrompt() geht deshalb einfach so:
printf ">"
}
function showAndPrompt(i){
system("start microsoft-edge:" ln[i]);
prompt()
}
Wie startet die ganze Sache? Ich füge am Ende des BEGIN-Blocks einen Aufruf showAndPrompt(i = 2) ein, damit das erste Bild schon mal aufgeht (die erste Zeile der CSV-Datei ist eine Kopfzeile). Nach dem Öffnen eines neuen Browser-Fensters beweist ein Aufruf
gawk -f sik.awk -v csvfile=SIK_01.sorted.csvdass alles funktioniert!
Navigation
Die ersten Befehle dienen nun dazu, das nächste und vorherige Bild anzuzeigen ...
/^\+$/ {..., auch mal weiter zu springen ...
showAndPrompt(++i)
next
}
/^-$/ {
showAndPrompt(--i)
next
}
/^[+-][0-9]+$/ {... und ein bestimmtes Bild anzuzeigen:
showAndPrompt(i += 0 + $0)
next
}
/^[0-9]+$/ {Das kann man nun schon einmal fröhlich ausprobieren (Enter schließt die Befehlseingabe ab, Alt-Tab wechselt jeweils vom Browser zurück zur Command-Line):
showAndPrompt(i = 0 + $0)
next
}
gawk -f sik.awk -v csvfile=SIK_01.sorted.csv... Achtung – nicht dem Immer-Weiter-Blätterwahn verfallen! Da ist noch einiges zu tun.
>+Enter
Alt-Tab >–Enter
Alt-Tab >314Enter
Alt-Tab >-3Enter
Alt-Tab >+Enter
Alt-Tab >+Enter
Alt-Tab >+Enter
Alt-Tab >
Zumindest einen Befehl zum Beenden brauchen wir noch – schnell ergänzt:
/^q$/ {
exit
}
... und eine letzte Zeile, wenn man was eingibt, was das Programm nicht versteht:
{
print "???"
prompt()
}
Ergonomie und Psychologie 1
Ein "perfektes Blättern" würde mit einem einzigen Tastendruck erfolgen – mein Toolchen braucht vier: + Enter Alt Tab. Wenn aber beide Hände passend auf der Tastatur liegen, dann kann man diese Tasten ohne viel Bewegung drücken: + Enter geht mit Ringfinger und kleinem Finger der rechten Hand (sowohl auf der normalen wie auf der numerischen Tastatur), Alt Tab mit Daumen und Ringfinger der linken Hand (evtl. nach ein wenig Übung). Ergonomisch sind das damit "nahezu" nur zwei zu drückende Tasten. Ganz selten allerdings irren sich meine Finger rechts, und ich drücke Enter vor +: Dann erhalte ich die Fehlermeldung ???, und ein + steht da und nichts passiert ... da muss noch was verbessert werden. Wie das geht, kommt gleich.
Damit kommen wir zur Psychologie: Tatsächlich bevorzuge ich die zwei getrennten "Befehle" +Enter für das Weiterblättern und Alt-Tab für das Zurückschalten zur Befehlszeile: Denn mir scheint, dass man sich tatsächlich in einem von zwei verschiedenen "Modi" befindet: Entweder dem "Bildmodus" oder dem "Befehlsmodus"; diese beiden Befehle schalten dazwischen ganz explizit hin und her. Ich komme später zu einem Befehl, wo ich eine Zeitlang "gestolpert" bin – erst eine Änderung des Befehlsverhaltens wegen dieser Modus-Sache hat diesen "Schluckauf" repariert.
Das falsche Drücken Enter +, nach dem man auf das nächste Bild wartet, ist genau deswegen unangenehm: Man ist im Kopf im Bildmodus, das Programm ist aber noch im Befehlsmodus – es dauert "ewig", bis man das kapiert und reagiert. Die korrekte Reaktion ist nun ein alleiniges Enter – da aber +Enter längst im Kopf als "ein Befehl" abgespeichert ist, drückt man das nun noch einmal – und erhält (wegen der resultierenden Eingabe von ++Enter) nun eine Fehlermeldung! Auch wenn dieser Fall bei einiger Übung nur sehr selten auftritt, hilft es dennoch, wenn man den +-Befehl dafür erweitert: Auch zwei +-Zeichen sollen erlaubt sein – oder gleich mehrere:
/^\++$/ {
showAndPrompt(++i)
next
}
Noch zwei "psychologische Punkte":
- Die Bilder sind im Programm durch ihre CSV-Nummer identifiziert; im Bildmodus, also auf der Seite der ETH-Bibliothek, sieht man diese aber nicht. Tatsächlich braucht man sie dort auch nicht, sondern nur im Befehlsmodus (u.a. wenn man dort eine CSV-Nummer zum Springen angeben will). Man sollte diese Information also explizit machen – dazu erweitere ich prompt():
function prompt(i) {
printf "%d>", i
}
- Auf der ETH-Seite erscheint i.d.R. (zumindest bei mir) ein englischer Bildtext, der außerdem sehr häufig eher schlecht (weil wörtlich übersetzt) ist. In den CSV-Dateien steht der bessere deutsche Originaltext – ihn will ich auch sehen. Dazu ändere ich die prompt()-Funktion noch einmal:
function prompt(i) {
Tatsächlich befriedigt eine solche Ausgabe nicht: Die kombinierte Information
printf "%d %s\n>", i, tx[i]
}
123 Kanton ZH, Zürich, SBB Depot, C5/6 2953;;1/1966-2/1966;
muss ich gedanklich wieder in "Zahl" (123) und Text (alles danach) zerlegen: Ein unnötiger Denkaufwand (später werden wir sehen, dass solche Vorgänge wichtigere Denkabläufe so stark stören können, dass man praktisch nicht effizient arbeiten kann). Nach mehreren Ausgabe-Versuchen, bei denen ich jeweils mit einem ganz kurzen Blick die beiden Informations-Stücke "direkt sehen" wollte, bin ich nun bei folgender Version angelangt:function prompt(i) {
was folgende Ausgabe ergibt:
printf "\n%s\n%d>", tx[i], i
}
2>+121
Die CSV-Nummer 123 ist hier klar abgegrenzt vom Informationstext darüber (wie lange der auch immer ist – manche sind sehr lange). Und die Leerzeile macht klar, zu welcher CSV-Nummer der Text gehört.
Kanton ZH, Zürich, SBB Depot, C5/6 2953;;1/1966-2/1966;
123>
Das "Ergebnismodell"
Der eigentliche "Stakeholder" des Bearbeitungsergebnisses bin nicht ich als Ersteller der "SIK-Sicherungsanlagen-Aspekte-Liste", sondern "ein Leser" (der wieder ich sein mag, in mittlerer Zukunft – aber das ist dann "ein anderes Ich"). Wie sollen ihm oder ihr die Ergebnisse präsentiert werden? In einer ersten Version habe ich alle passenden Bildcodes und meine Beschreibungen dazu aufgelistet; tatsächlich ist das aber viel unübersichtlicher, als das Ergebnis "eigentlich" ist: Denn ganz häufig folgen im Bilder-Konvolut eine ganze Reihe von Bildern aufeinander mit denselben Motiven; und eine solche Reihe sollte man dem Leser daher auch als "einen Block", mit einer Beschreibung präsentieren. Da ein "Weiterblättern" nach meiner(!) Definition der Reihenfolge, nämlich nach aufsteigendem Bildcode, auf der ETH-Seite nicht möglich ist, muss ich aber trotzdem alle DOI-Links einer solchen Reihe im Ergebnis hinterlegen: Daraus hat sich die Präsentation ergeben, die man in den beiden vorherigen Postings sieht.
Tatsächlich sieht man dort allerdings in einem Block nicht direkt eine aufsteigende Reihe, sondern eben eine Menge von Links – man könnte dort also auch nicht-aufeinanderfolgende Bilder zusammenfassen! Soll man, oder soll man nicht?
Ich lasse hier den Bearbeiter-Stakeholder "gewinnen": Die Effizienz des linearen Durcharbeitens ist so wichtig, dass sie auch definiert, was im Ergebnis auftaucht. Das mentale Modell beim Durcharbeiten ist also folgendes:
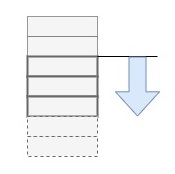
Der zugehörige Bearbeitungsprozess läuft offensichtlich im Happy-Day-Fall so:
- Beim linearen Durchblättern will ich bei einem bestimmten Bild eine "Anfangsmarkierung" für einen Block setzen.
- Durch Weiterblättern mit + "akkumuliere" ich weitere Bilder in den Block.
- Wenn ich auf ein Bild stoße, das nicht mehr zum bisherigen Block passt, will ich für den Gesamtblock einen Beschreibungstext erfassen und ein HTML-Snippet ausgeben, das "irgendwie" in die Ergebnisdatei gelangt.
/^m$/ {Die Ausgabe erfolgt mit einem Befehl p, dem der Beschreibungstext folgt:
m = i;
prompt(i)
next
}
/^p/ {Eine Bearbeitungssequenz für einen Block sieht also so aus:
Ausgabe von Bildcode id[m] mit Link ln[m]
for (j = m + 1; j < i; j++) {
Ausgabe von # mit Link ln[j]
}
Ausgabe von substr($0, 2)
prompt(i)
next
}
...>mEnter
...>+Enter
Alt-Tab...>+Enter
Alt-Tab...>+Enter
Alt-Tab...>+Enter
Alt-Tab...>pWeichen, Zürich, CH, 1999Enter
...HTML...
Kopieren des angezeigten HTML in die Ergebnisdatei
Ergonomie und Psychologie 2
Ergonomisch ist das mindestens "genügend angenehm": mEnter lässt sich mit Zeigefinger und kleinem Finger der rechten Hand als "eine Bewegung" eingeben. p liegt genau unter meinem Mittelfinger, danach muss ich in die "Schreibhaltung" gehen, um den Beschreibungstext zu erfassen; Enter lässt sich zum Abschluss des Textes effizient mit dem kleinen Finger eingeben. Das Kopieren des Textes ist allerdings bisher sehr "disruptiv"...
... hier ist eine Verbesserung nötig, die ich bisher noch nicht realisiert habe. Prinzipiell kann man das HTML-Snippet an die Ergebnisdatei einfach anhängen – die Praxis zeigt aber, dass ich immer wieder Tippfehler mache, sodass eine nachträgliche Korrektur des Textes nötig ist. Mit Pfeil nach oben kann man den vorherigen p-Befehl elegent "wieder herholen", danach (allerdings ergonomisch nicht sehr effizient) korrigieren – das erneute Schreiben in die Ergebnisdatei müsste nun aber den vorherigen Text entfernen, was technisch ein wenig tricky ist. Das ist aktuell ein "To Do" (das ich aber für die Bilder ab 20000 auf jeden Fall gelöst haben will).
Wie sieht es mit der Psychologie aus? Drei Effekte sind mir aufgefallen:
- Ich will den "Block-Bereich" m...i sehen. Dazu habe ich prompt() ein weiteres Mal erweitert:
function prompt(m, i) {
Die Ausgabe sieht dann z.B. so aus:
printf "\n%s\n%d..%d>", tx[i], m, i
}
110..111>+12
Damit ist der Block-Bereich "etwas sichtbarer" (auch wenn man lernen muss, dass er vor der zweiten Zahl endet: Also der Block im Beispiel die Bilder 110 bis 122 umfasst).
Kanton ZH, Zürich, SBB Depot, C5/6 2953;;1/1966-2/1966;
110..123>
- Das m für die Markierung war für mich immer auch mit dem Weiterblättern zum nächsten Bild verbunden: Ich habe, mich selbst beobachtend, festgestellt, dass ich nach Eingabe von mEnter einen Moment warte und erst nach kurzem "Aha!" +Enter eingebe. Offenbar bin ich also nach m schon im Bildmodus, das Programm aber noch im Befehlsmodus. Die Ergänzung des m-Codes um die +-Logik hat das Arbeiten dann tatsächlich "richtig flüssig" gemacht:
/^m$/ {
m = i;
showAndPrompt(m, ++i)
next
}
- Beim "Block-Aufsammeln" der Bilder schaue ich mir jedes Bild an und baue im Kopf die Beschreibung zusammen: "Aha, Weichen..." + "...und Drahtzugleitungen..." + "...nichts Neues..." + "...und ein Gefälleanzeiger..." + "...und Ende (des Blocks)!". Diese Worte bleiben nur im Kurzzeitgedächtnis; das funktioniert also nur, wenn eher wenige Bilder (bis zu etwa vier) im Block sind und wenn mein Bilder-Analysieren nicht zu anspruchsvoll wird: Ein Gedanke "Was ist denn das da??" stört schon enorm und löscht häufig die akkumulierte Beschreibung im Kopf. Abhilfemöglichkeiten sind u.a.:
- Wenn ich merke, dass ich "verzögere", sage ich mir die Beschreibung einmal deutlich vor – dadurch "lerne ich sie als Text". Das reicht oft, damit sie zumindest einen "intensiveren Such-Denk-Vorgang" überlebt.
- Weil p den m-Wert und (bisher) die Ergebnisdatei nicht verändert ("idempotent bzgl. des internen Zustandes ist", für Fachleute), kann ich einen p-Befehl für den bisherigen Teil des Blocks absetzen, dessen Ausgabe als "persistenter Speicher" dient.
- Wenn das Kurzzeitgedächtnis zu schwanken beginnt: Lieber den Block abschließen!
- Vielleicht sollte ich aber einen explizit gespeicherten Textwert einführen, mit Set- und Retrieve-Möglichkeiten ... muss ich einmal versuchen!
- "Wenn alle Stricke reißen", muss ich nach der Bildanalyse zurück zum ersten Bild des Blocks springen und den Block neu "aufbauen". Dazu habe ich einen eigenen Befehl l (ein kleines L) ergänzt:
/^l$/ {
Die Ergonomie von l ist ganz gut (rechter Mittelfinger, dann kleiner Finger für Enter). Psychologisch ist anzumerken, dass man diesen Befehl nur sehr selten braucht und man ihn daher "explizit abrufen muss". Meine Eselsbrücke ist: "l ist (alfabetisch) links von m" = "das Gegenteil von m". Bisher komme ich damit zurecht.
showAndPrompt(m, i = m)
next
}
Weitere Punkte
Das war im Wesentlichen die Erklärung des zentralen Prozesses, der "Blockakkumulierung". Allerdings gibt es noch eine Reihe von teils gelösten, teils aber auch nicht gelösten Problemen:
- Die Einträge in der Ergebnisdatei sollten ja mit den "Tags" [A] und [I], [S] und [B], [D]/[V]/[E] und [!] gekennzeichnet werden. Diese Information entsteht als Teil des inhaltlichen Aufakkumulierens, sie soll daher auch mit der Erstellung der Beschreibung "abgeliefert" werden. Tatsächlich habe ich daher nicht einen p-Befehl implementiert, sondern die Angabe eines oder mehrerer Zeichen aus {aisbdve!} leitet eine Beschreibung ein:
/^[aisbdve!]+/ {
Ausgabe der Tags als HTML
Ausgabe von Bildcode id[m] mit Link ln[m]
for (j = m + 1; j < i; j++) {
Ausgabe von # mit Link ln[j]
}
Ausgabe von $0 nach erstem Leerzeichen
prompt(m, i)
next
}
- Hans-Peter Bärtschi hat nicht nur Eisenbahnen fotografiert, sondern – je später, desto mehr – sich allen Bereichen der Industrie- und Architekturdokumentation gewidmet. Es gibt beeindruckende und lange Bildsequenzen z.B. des Gaswerks in Schlieren, ganzer Ortschaften mit all ihren Straßen und Häusern, noch aktiver und stillgelegter Textilindustrieanlagen (Spinnereien, Textildruckereien und mehr), Mühlenanlagen und noch viel mehr. Das ist alles interessant – aber für meine Zwecke irrelevant; und ich muss solche Sequenzen effizienter als durch ewiges +-Drücken "überwinden". Hier kommen die CSV-Dateien wieder ins Spiel: Wenn ich feststelle, dass einige eisenbahnfremde Bilder aufeinanderfolgen, gehe ich in der (immer geöffneten) CSV-Datei in die entsprechende Zeile (Alt-Tab Alt-Tab zum Wechsel in den Editor, Ctrl-G 123Enter geht dort in die Zeile gemäß der CSV-Nummer) ...
... und entscheide dort anhand der Bildtexte, in welcher Zeile ich mit meiner Arbeit fortsetze; diese Zeilennummer gebe ich als CSV-Nummer im Toolchen an – und weiter geht es! Allerdings muss ich da etwas vorsichtig sein: Z.B. hat sich mitten unter Bildern mit dem summarischen Titel "Lodz, Textilmuseum, Briefkopf Bidermann ua., PKP-Dampfloks Warschau Breslau Waldenburg" zwischen Plänen und Anzeigen von Textilfirmen aus Lodz diese Aufnahme eines preußischen Kreuzflüglers befunden! Dort hat mich aber immerhin das "PKP-Dampfloks" im Titel überredet, mir auch diese Bilder einzeln anzusehen. Am Ende jeder meiner Beschreibungen steht immer Ort, Land, Jahr. Diese Werte ändern sich auch von Block zu Block nur selten, und wenn, dann am häufigsten der Ort, seltener das Land(eskürzel), am seltensten das Jahr. Hier gibt es bisher einen "psychologischen Mismatch": Denken tu ich mir "dasselbe wie beim letzten Block", schreiben muss ich aber die Information immer wieder.
Eine Abhilfe, die ich auf jeden Fall versuchen will, könnte die Angabe von ### oder ## oder # am Ende der Beschreibung sein, jeweils für "alle drei Werte von der letzten Blockbeschreibung übernehmen", "Land und Jahr übernehmen" sowie "Jahr übernehmen".
Die ETH-Bibliothek hat mich gebeten, im Rahmen von Mitmachen Korrekturanmerkungen zu Bildern zu erfassen. In einem ersten Versuch wollte ich das direkt in die Blockakkumulierung integrieren (mit einem eigenen Befehl, wo ich einen verbesserten Text irgendwohin speichern kann). Technisch und ergonomisch ist das problemlos – aber die Psychologie spielt nicht mit: Der inhaltliche Akkumulierungsprozess braucht "meinen ganzen Denkapparat"; eine "Abzweigung zu einem anderen Aspekt" killt das Kurzzeitgedächtnis, und "alles steht".
Eine mögliche Abhilfe ist, mit einem zusätzlichen Markierungsbefehl "unterhalb der Denkschwelle" einen Text als "falsch" zu kennzeichnen (j würde ergonomisch noch akzeptabel liegen). Die – experimentell zu klärende – Frage ist, ob sogar das zu disruptiv ist. Wenn ja, dann könnte man vielleicht den ganzen Block nach dem p kennzeichnen: Aber dann müsste man sich dieses eine Bit mit Bedeutung "falsch" parallel zur Blockakkumulierung merken, was meiner Meinung nach nicht funktioniert: Zwei noch so kleine, aber nicht miteinander verknüpfte Informationsstückchen sind im Kurzzeitgedächtnis nicht möglich. Dann wäre die dritte Möglichkeit nur ein "Nachlesen" der Beschreibungen (die ja im Befehlsmodus sichtbar sind!) und nachträgliches "Neuentscheiden", ob ein Kommentar nötig ist.
An dieser Stelle beende ich meine Beschreibung einmal. Erst wenn ich mich den nächsten 10000 Bildern widme, werde ich hier Fortschritte machen.
Keine Kommentare:
Kommentar veröffentlichen